- Home
- Hochschule
-
Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Erstattung
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester- und Vorlesungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche
- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
- Hochschule
- Studium
- Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Erstattung
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester- und Vorlesungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche

- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
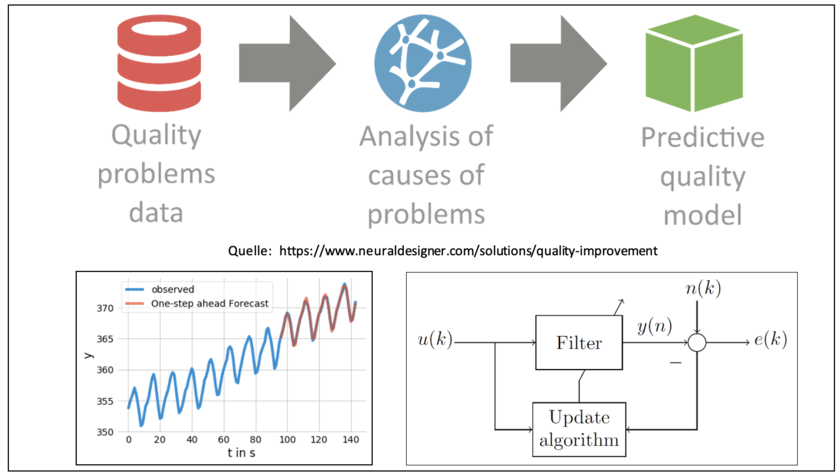
Lernverfahren zur Qualitätsprognose in der Fertigung
Projektübersicht
| Anzahl Studierende | 1 |
| Art | gefördertes Projekt mit externem Partner |
| Projektverantwortung | Prof. Dr.-Ing. Martin Kohlhase |
| Projektkontext |
Projekt in Zusammenarbeit mit der Firma Miele & Cie. KG in Gütersloh und dem Center for Applied Data Science Gütersloh (CfADS). Eine parallele Anstellung als WHK am CfADS ist möglich. |
| Projektdurchführung |
Marcel Hanitz |
Kurzbeschreibung
In zahlreichen Industriezweigen werden verschiedene Bauteile in automatisierten Anlagen zu Baugruppen zusammengesetzt. Unabhängig von den eingesetzten Technologien gibt es in allen Anlagen Mindestanforderungen, die das Erzeugnis erfüllen muss. Üblicherweise werden diese Mindestanforderungen durch Toleranzen beschrieben. Die Einhaltung von vorgegebenen Toleranzen wird dabei von zahlreichen Faktoren beeinflusst. So wirken sich unter anderem die Konstruktion der Bauteile, die Toleranzen der einzelnen Rohteile, die Parameter des Fertigungsprozesses und die Konstruktion der Fertigungsanlage auf das Erzeugnis aus. Insgesamt ergeben sich viele Ursache-Wirkungs-Zusammenhänge in der Anlage, die nur schwer zu erfassen und zu verstehen sind. Die Vielzahl der Einflussfaktoren sorgt für eine hohe Komplexität bei der Bedienung der Anlage und setzt ein detailliertes Wissen über die individuellen Eigenschaften und das spezifische Verhalten der Anlage voraus. Beim Auftreten von Qualitätsproblemen ist die Identifikation der Ursachen daher eine große Herausforderung. Außerdem führen Qualitätsprobleme sofort zu einer sofortigen Nachbearbeitung oder zu Ausschuss und folglich auch zu einem höheren Arbeitsaufwand. Außerdem wird unnötig Energie und Material verbraucht, sowie Fertigungskosten verursacht.
Die Motivation des Forschungsprojekts liegt in der Online-Auswertung von Fertigungsdaten, Daten aus dem ERP-System und Daten von Kundengeräten, die in der Cloud zusammengeführt werden und die Qualität der aktuell produzierten Baugruppen, Komponenten oder sogar des gesamten Produkts bewerten und in Echtzeit anzeigen. Die Bearbeitung des Projekts erfolgt in enger Zusammenarbeit mit der Firma Miele & Cie. KG, aus deren Fertigung reale Daten zur Verfügung gestellt werden. Die Daten werden mittels Data-Mining-Verfahren verdichtet. Anhand der verdichteten Daten werden Datenmodelle für die Qualitätsprognose trainiert und erzeugen online die notwendigen Kenngrößen für die Produktion. Durch anwenderfreundliche Visualisierungskonzepte werden sowohl dem Qualitätsmanager als auch dem Werker vor Ort die wichtigsten Informationen und Handlungsempfehlungen angezeigt. Durch eine „ergonomische“ Visualisierung von Handlungsanweisungen für den Werker entsteht ein Assistenzsystem (Smart Service), das den Menschen entlastet, schnellere Durchlaufzeiten in der Produktion ermöglicht, den Ausschuss und die Nacharbeit reduziert und die Produktqualität verbessert. Gleichzeitig wird der Produktionsprozess transparent und es können weitere Optimierungspotenziale erschlossen werden.
Aufgabenstellung
Entwicklung und Anwendung von Online-Verfahren zur Modellierung qualitätsrelevanter Merkmale anhand eines realen Fertigungsprozesses.
Im Rahmen dieser Tätigkeit sollen verschiedene Online-Verfahren zur Klassifikation und Regression für die Prognose qualitätsrelevanter Merkmale ausgewählt, analysiert und weiterentwickelt werden. Neben realitätsnahen Testprozessen, wie sie auch in der IoT-Factory des CfADS zu finden sein werden, sollen die entwickeltenAlgorithmen in die Anwendung überführt und auf Daten aus der Fertigung der Firma Miele angewendet werden. Die erstellten datenbasierten Modelle bilden damit wichtige Bestandteile des Werkerassistenzsystems. Die Bearbeitung erfolgt in enger Zusammenarbeit mit dem Team des Center for Applied Data Science der HSBI.
Bezug zum Thema Data Science
Im Rahmen der Tätigkeit soll der Studierende in Zusammenarbeit mit den Mitarbeitern des CfADS bei derRealisierung eines Data Science Workflow mitwirken. Es werden reale Daten mittels Data-Mining- Verfahren verdichtet und für die Erstellung von datenbasierten Modellen verwendet. Hierbei werden verschiedenste Verfahren aus dem Bereich des maschinellen Lernens angewendet. Außerdem sollen die Daten unter Verwendung der Cloud-Plattform des CfADS verarbeitet werden. Diese Cloud-Plattform basiert auf dem Hadoop-Framework, so dass hierbei Methoden aus dem Bereich Big Data angewendet werden können. Damit können zahlreiche Kompetenzen, die der Studierende in den Veranstaltungen des Forschungsmasters erwirbt, in der Praxis angewendet werden.
Verfügbare Ressourcen
Für die Bearbeitung des Projekts kann die Infrastruktur des CfADS genutzt werden, die aus folgenden Komponenten besteht, bzw. bestehen wird:
- Data-Analytics-Cluster: rechenstarker Computercluster auf Basis des Hadoop-Frameworks
- IoT-Factory: Modellfabrik zur Nachbildung realer Produktionsabläufe
- Smart Service Lab: Labor zur Entwicklung von Smart Services und Assistenzsystemen auf Basis von Smart Devices.
Die notwendige Datengrundlage kann durch die Nutzung der IoT-Factory geschaffen werden. Außerdem kann aufFertigungsdaten der Firma Miele zugegriffen werden. Die dafür notwendige Schnittstelle und Methoden zur Vorverarbeitung wurden im Rahmen eines laufenden Forschungsprojekts entwickelt.
Projektplan
Erstes Semester:
Einarbeitung in die CfADS Infrastruktur und die zu betrachtenden Prozesse, Literaturrecherche und Einarbeitung in Online-Verfahren zur Klassifikation und Regression, Formulierung des Forschungsexposés.
Zweites Semester:
Implementierung erster Online-Verfahren, Untersuchung der Verfahren anhand von Testprozessen, Erstellung eines Papers, das einen Überblick über das jeweilige Forschungsgebiet gibt.
Drittes Semester:
Data-Mining in den realen Fertigungsdaten, Anwendung ausgewählter Verfahren auf die realen Daten, Erstellung eines Papers mit ersten quantitativen Ergebnissen.
Viertes Semester:
Entwicklung weiterer Algorithmen und Optimierung des Gesamtverfahrens, Auswertung der Güte und Evaluierung der Ergebnisse, Masterarbeit und Kolloquium.
Eignungskriterien
Zwingend:
- Grundkenntnisse der Informatik
- Programmierkenntnisse, insbesondere Python oder Matlab
- Teamfähigkeit und Interesse an wissenschaftlicher Arbeit
Optional:
- Praktische Erfahrungen mit Fertigungsanlagen
- Grundkenntnisse der Regelungs- und Automatisierungstechnik
Erwerbbare Kompetenzen
- Anwendung verschiedener Data-Mining-Verfahren
- Maschinelle Lernverfahren, insbesondere Online-Verfahren
- Big-Data Workflows unter Verwendung des Hadoop-Ökosystems
- Aufbereitung / Darstellung von Analyseergebnissen
- Kommunikationsstandards wie OPC UA oder MQTT